隨著大數據時代的來臨,SQL Query 成為了各行各業不可或缺的必備技能。然而對於不熟悉 SQL 語法的使用者而言,將自然語言問題轉換為複雜的 SQL 查詢是一項巨大的挑戰。為了解決這個問題誕生了 Text-to-SQL 技術。這項技術的目標是讓使用者能夠以日常語言直接詢問資料庫,系統則會自動生成相應的SQL查詢,從而大幅提升資料檢索的效率與便利性。
近年來,隨著人工智慧技術的飛速發展,大規模語言模型(LLMs)如 GPT-4、LLaMA 等的出現,為 Text-to-SQL 領域帶來了前所未有的突破。這些模型透過海量的文本訓練,展現了卓越的自然語言理解能力,讓過去依賴大量手動規則的 Text-to-SQL 技術進化到依賴模型智能生成的全新階段。這不僅讓非技術背景的使用者更容易使用SQL Query,還大大提升了查詢的準確性與效率。
儘管如此,如何設計有效的提示工程(Prompt Engineering)以引導這些模型生成正確的 SQL 查詢仍是目前的研究重點。這個領域的持續創新,不僅有望讓更多的開源模型參與其中,還能讓 Text-to-SQL 技術應用到更廣泛的實際場景中。如果您對這項技術感到興趣,接下來的內容將深入探討這些模型的最新進展與技術應用,為您揭示這一領域的潛力與挑戰。
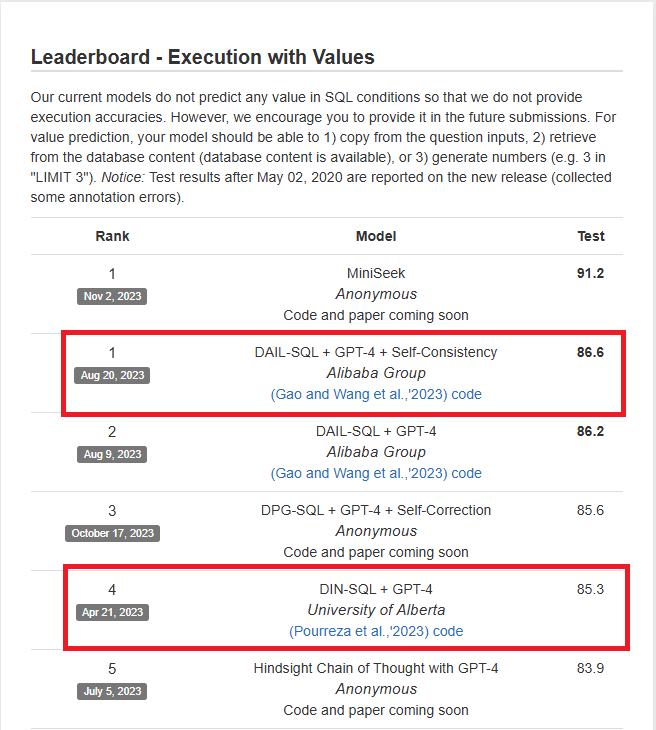
前面我們先介紹了基本的 Text-to-SQL 方法,如果你套用現實中的 DB Table 的話會發現很多小問題。現實應用上我們不可能只針對單一表格查詢,經常會使用到多表 JOIN、GROUP BY、Subquery等進階方法,因此我們需要更深入探討解決方法。本篇將會透過兩篇 Text-to-SQL 競賽前幾名的論文來探討 Prompt Engineering 的方法。
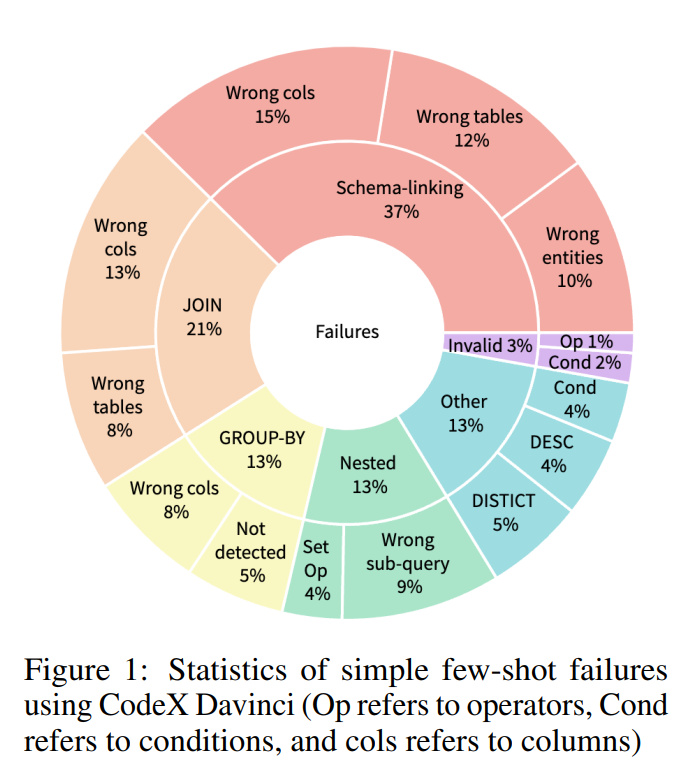
Schema Linking
定義:這個類別包含模型未能正確識別問題中提到的列名、表名或實體的情況。某些情況下,查詢需要聚合函數,但LLM選擇了匹配的列名(Column Name),而不是執行計算操作。
範例:當問題是「所有體育場的平均和最大容量是多少?」時,資料庫架構中有一列名為「Average」,模型錯誤地選擇了這一列,而不是計算「Capacity」列的平均值。
JOIN
定義:這是第二大類錯誤,包括需要JOIN的查詢,LLM不能將外鍵(FK)正確的匹配。
範例:模型可能未能識別查詢所需的所有表或正確的外鍵,導致JOIN操作失敗。
GROUP BY
這個類別包括需要GROUP BY語句的情況,但LLM選擇了錯誤的column進行分組。
Queries with nesting and set operations
這個類別包括使用nesting或set operations,但LLM未能正確的識別nesting或set operations。
Invalid SQL
LLM生成的語法有錯誤,導致這些語句無法執行。
Miscellaneous
這個類別不屬於上述任何一個類別的情況。例如多餘的條件、缺少條件、缺少或多餘的 DISTINCT或DESC關鍵字,以及WHERE子句缺失或查詢包含冗餘的函數。
我們可以發現有超過 1/3 跟 LLM 針對表格名稱和問題的理解錯誤,因為我們在實際命名資料庫欄位名稱時,通常不會表達出其完整含義,這邊可以透過 Comment、Description 等方法去針對欄位補充意思。而 JOIN、GROUP BY 等進階查詢語法也無法使用同一個 Prompt 解決所有問題,必須詳細拆解。
主要想法為先找出要使用的【欄位名稱、表名稱】→問題【難度分類】→依照不同難度用不同 Prompt【生成語法】→【檢查語法正確性】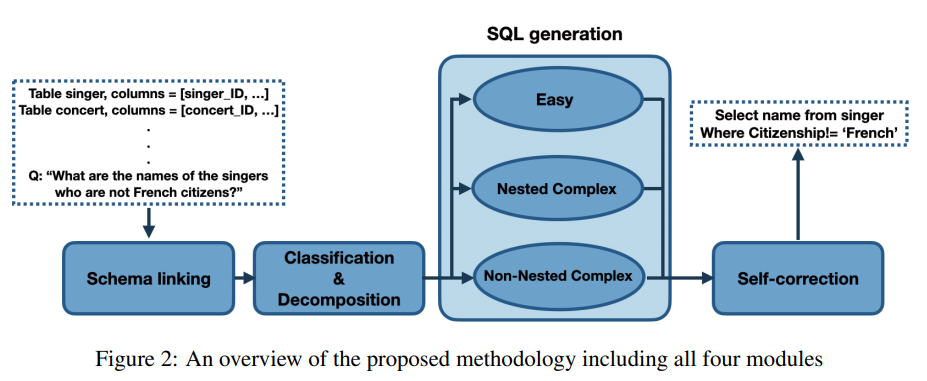
Schema Linking(10 shot)
Schema linking 主要功能是透過 LLM 匹配 DataBase Schema 和 SQL Syntax 的欄位名稱、數值。
例如查詢「有哪些體育場超過50000個座位?」,LLM可以推理出需要使用到「體育場.名稱、體育場.容量」並將「50000」作為條件值。
Prompt: 使用chain-of-thought(CoT) + 10 shot技巧來實現。
Classification(10 shot)
針對問題分成三個等級,解決 LLM 無法使用同一個 Prompt 生成所有難度的 SQL 查詢,下一步驟對應三種不同的Prompt。
SQL Generation(10 shot)
因應不同等級的問題,需要由三種不同的 Prompt 來解決。
Self Correction
此步驟主要在執行 Query 前做最終的語法修正,改善 LLM 生成的語法錯誤。
Text-to-SQL 技術的發展結合了大型語言模型(LLMs)的進步,為資料查詢帶來了革命性的變革。透過 LLM 的自然語言理解能力,Text-to-SQL 可以讓非技術背景的使用者輕鬆地以日常語言發出查詢需求,而系統則能自動生成精確的 SQL 語句,極大地提升了資料檢索的便捷性與效率。
然而,Text-to-SQL 並非萬能,在應對複雜查詢時仍存在挑戰,如表名與欄位名稱匹配的錯誤、進階查詢語法如 JOIN 和 GROUP BY 的不正確使用等。這些挑戰反映出如何進一步優化提示工程(Prompt Engineering)對於提升 LLM 的準確性和查詢結果的重要性。隨著研究的持續深入,未來的 Text-to-SQL 技術將變得更加智能和高效,並廣泛應用於各行各業的資料處理需求。
最終,Text-to-SQL 的發展不僅降低了查詢資料的技術門檻,還提供了強大的工具來應對各種業務需求,為企業的資料決策提供有力支持。隨著這項技術的成熟,未來它將在更多場景中發揮重要作用。


 iThome鐵人賽
iThome鐵人賽